文|周文斌
英伟达、AMD将断供中国高性能GPU芯片,卡脖子又有了新的花样?
今日一早,有媒体报道英伟达发布公告,表示之后向中国(包括香港)和俄罗斯的客户出口两款高端GPU芯片A100和H100需要新的出口许可。一纸公告引发人工智能和芯片半导体两个行业的双重地震。
事实上,我国高端GPU芯片进口从2019年以来就一直有被限制,只是之前主要针对的厂商是AMD;而在应用场景上又以超算中心为主,所以企业和消费者在产品端的感知并不强。
而这一次范围扩大之后,许多互联网大厂也就受到了影响。因为以A100芯片为例,其主要应用场景除了超算中心之外,还包括云计算服务器、数据中心、AI训练等场景。
实际上,随着国内云计算、以及互联网企业在云端储存,数据处理等方面需要的数据量越来越多。各大互联网企业、云厂商最近几年在AI芯片领域也都早有布局。
但国内大厂的AI芯片主要都是专用芯片,虽然在特定领域能够实现对英伟达的部分替代,但从产业全局来看,高端场景短期仍然很难摆脱对英伟达芯片的依赖。
当然,这也并不意味着国内云厂商和互联网大厂配置的英伟达服务器就要宕机,芯谋研究分析师商君曼对科创板日报表示,本次被限制的芯片处于一个很高端的位置,对国内企业的影响有限。
而在一些更普遍的应用场景,除了已经拥有的部分国产GPU芯片可以替代之外,英伟达的一些低端产品并不在限制范围内。国内大厂其实还有相当的时间可以辗转腾挪。
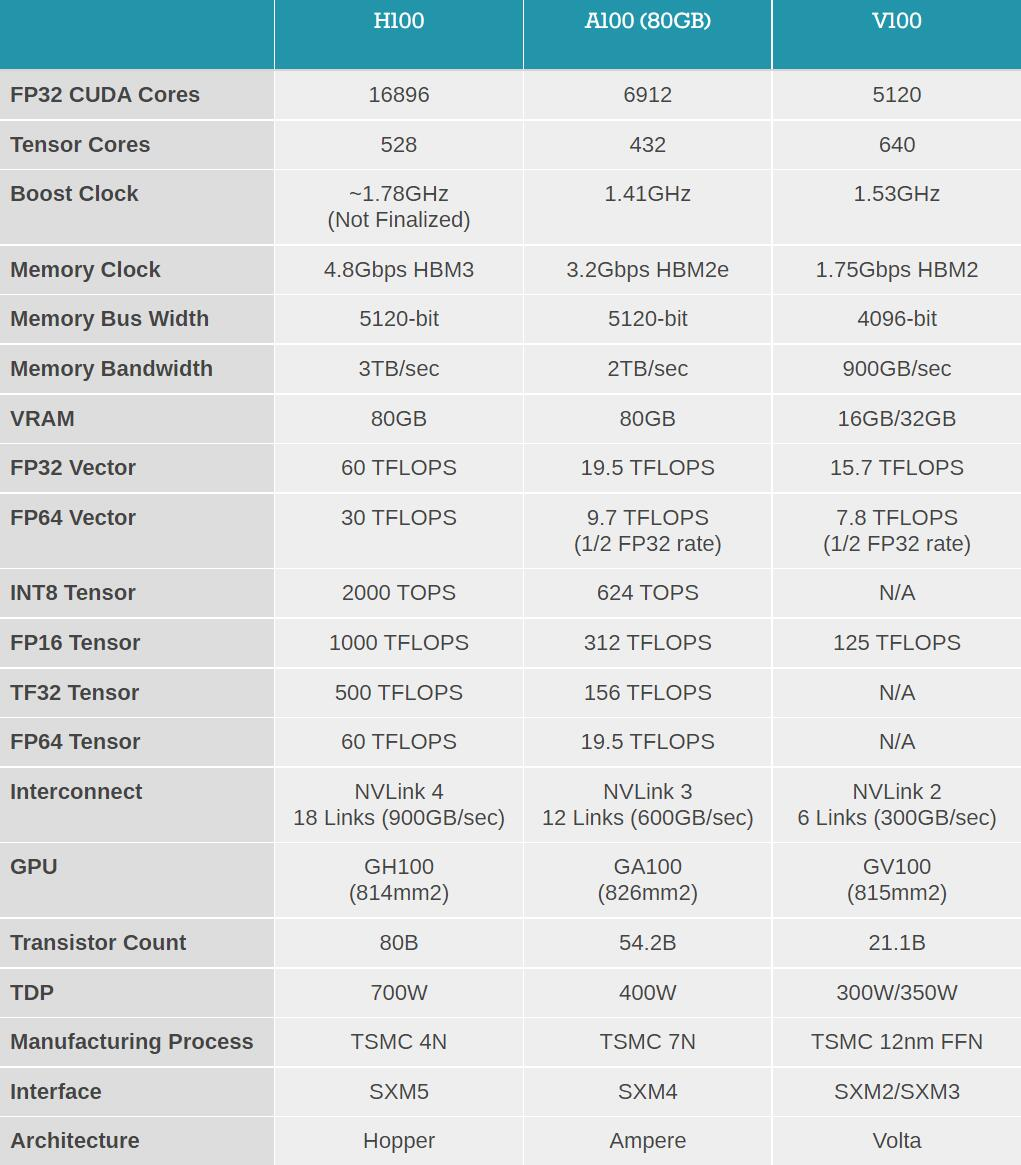
首先要讲清楚的是,这次针对英伟达被限制的GPU并不是常规意义上的显卡,而是非常高端的商用芯片,即A100和H100。这两款芯片都是专门针对 AI、数据分析和 HPC 应用场景研发的。
其中,A100芯片是2020年5月英伟达在GTC2020上发布的产品。A100是一块 3D 堆叠芯片,采用安培(Ampere)架构,应用了当时台积电最先进的7nm工艺,拥有 540 亿个晶体管,GPU 的最大功率达到了 400W,算力比上一代采用 Volta 架构的Tesla V100提升了20倍,号称当时全球最大的7nm芯片。
H100则是一款针对大模型专门优化的产品,在今年3月份在GTC大会上才发布,采用了最新的Hopper构架,应用的也是台积电最先进的4nm工艺,拥有800亿个晶体管,GPU最大功率800W。
除此之外,H100还加入了全新的Transformer Engine和可扩展性更高的Nvidia NVLink互连功能,用于提升大型AI语言模型、深度推荐系统等等。当然,目前H100还未正式进入商用。
图片来源:anandtech
目前,国内GPU高端场景的GPU应用基本上都由英伟达的A100覆盖,甚至今年3月份H100发布时,国内主流厂商也都已经预定。
比如,英伟达A100发布时,首批应用的OEM厂商包括浪潮、联想等企业;云服务公司也有阿里、腾讯、百度等主流厂商;而H100发布时,阿里云、百度云和腾讯云等厂商也都计划提供基于H100的实例。8月底,英伟达在第三财季展望上提到,这一块业务预计在中国有4亿美元的潜在销售。
这个情况在国外也是如此,包括AWS、Google Cloud、微软Azure、Oracle Cloud;或者思科、惠普等国际大厂采用的也都是英伟达的产品。目前,英伟达在数据中心 GPU 市场占比超过 80%,在云端训练市场上占比 90%,云端推理市场上占比 60%。
简单来说,就如同高通骁龙系列对于智能手机性能的决定性一样,英伟达的高端GPU芯片决定了云服务的性能和性价比,因此被国内外云厂商广泛采用。
当然,被广泛采用的另一个潜台词,其实是没有可替代的产品(同等性能上)。
比如在高性能计算方面,借助HBM2e每秒超过2TB的带宽和大容量内存,科研人员可以在A100上将原本要花费10小时的双精度模拟过程缩短到4小时之内。但在国内,目前没有芯片公司能够实现FP64的技术能力。
显然这一次美国对先进GPU的出口限制也将对中国的云厂商带来非常重大的影响。但从另一方面来说,这对中国自主GPU的发展也未尝不是一件好事。
虽然这次限制突如其来,但国内相关的云厂商和互联网大厂也并非全无准备。
早在几年前,随着国内云计算、以及互联网企业在云端储存,数据处理等方面需要的数据量越来越多。各大互联网企业、云厂商就已经在AI芯片领域开始布局了。
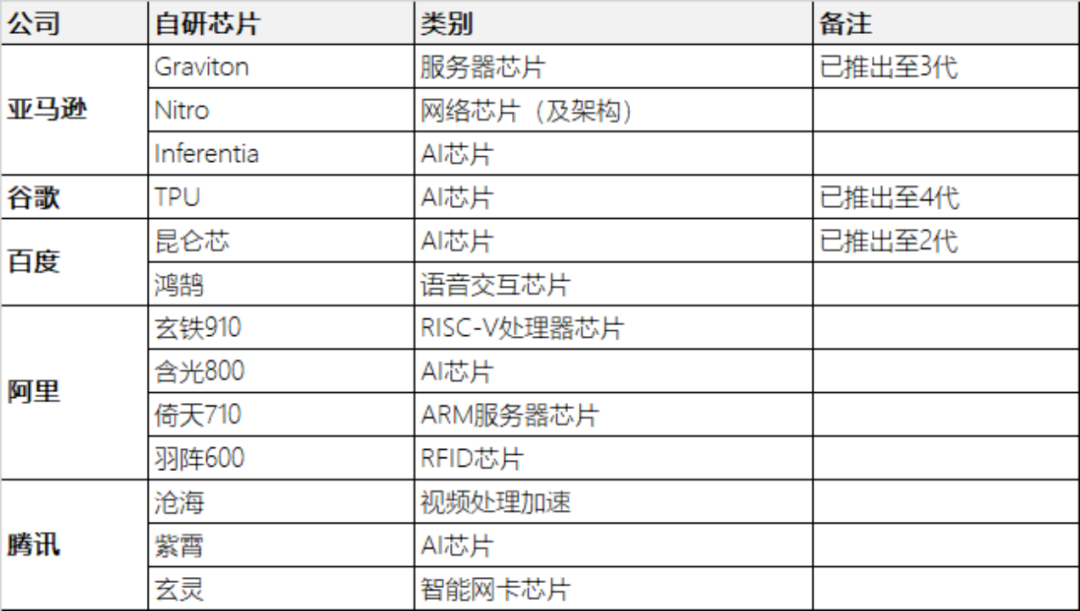
比如阿里在2019年发布了AI芯片含光800,百度在2020年量产了第一代AI芯片昆仑;稍微慢一点的腾讯也在2021年发布了视频处理芯片“沧海”和AI芯片“紫霄”。今年7月份,字节在“2022 火山引擎原动力大会”上也正式确认了其在自主造芯方面的布局。目前,字节的芯片研发已经涉足视频平台、信息和娱乐应用等。
虽然各大厂商进入芯片领域的时间有先后,但在具体的方向和应用场景上,大家的动作反而是出奇一致的。目前为止,国内互联网大厂研发的芯片,或者方向都集中在云计算,视频图像处理等方面的专用或者通用芯片上。
当然,大厂造芯除了解决技术自主问题之外,更重要的还在于成本和效率。
比如2019年阿里拍立淘商品库每天新增 10 亿商品图片,使用传统 GPU 算力识别需要 1 小时,但阿里同年推出的AI芯片“含光800”应用之后,这一时间被缩短到5分钟。
比如过去十年在云服务市场一直保持领先的亚马逊就因为通过自研服务器芯片Graviton替换英伟达来持续降低价格。据The Information报道,亚马逊的客户表示,他们通过租用Graviton服务器节省了10%~40%的计算成本。
事实上,不仅是阿里和亚马逊,如今的互联网大厂其实都面临着数据爆炸来带的处理效率、能耗以及成本的问题。对外提供云服务的企业更需要面对市场的竞争,不对外提供云服务企业也要考虑自身效率的提升。
比如现在的抖音,主屏已经从过去的底部4栏,顶部两栏扩充到底部4栏,顶部4栏等多个类目。而复杂的内容背后,往往意味着庞大的数据处理。
有数据显示,2017年抖音租借的服务器仅3万台,但到了2020就达到了42万台。除此之外,这一年字节在美国弗吉尼亚租还有一个可容纳10万台服务器的数据中心。
字节跳动主管火山引擎、数据中台的副总裁杨震原表示,如今字节 95% 的业务已经跑在自己的数据中心上。庞大的数据处理成为推动字节自研芯片的核心动力。
除了满足内部需要之外,以阿里、百度为代表的大厂其实也在将自研芯片向外进行“售卖”。比如阿里“含光800”虽然不对外售卖,但张建峰也提到:“含光 800 将通过阿里云对外输出 AI 算力,未来企业可以通过阿里云获取含光 800 的算力。”
基于云的芯片通过云走向市场。这其实也是为什么各大厂商的芯片主要都是自用的原因。当然,这种自用也并不是绝对的,毕竟现在各大厂商其实都在通过云服务的方式,将自身的能力分享给其他玩家。
比如张建峰也提到:“含光 800 将通过阿里云对外输出 AI 算力,未来企业可以通过阿里云获取含光 800 的算力。基于含光 800 的阿里云性价比提升了 100%。”
据调研机构Canalys发布的2022年一季度中国云计算市场报告显示,中国云市场总体规模达到73亿美元,同比增长21%。阿里云以36.7%的市场份额保持领先位置,华为云、腾讯云、百度智能云分别以18.0%、15.7%、8.4%的市场份额位居第二至第四位。
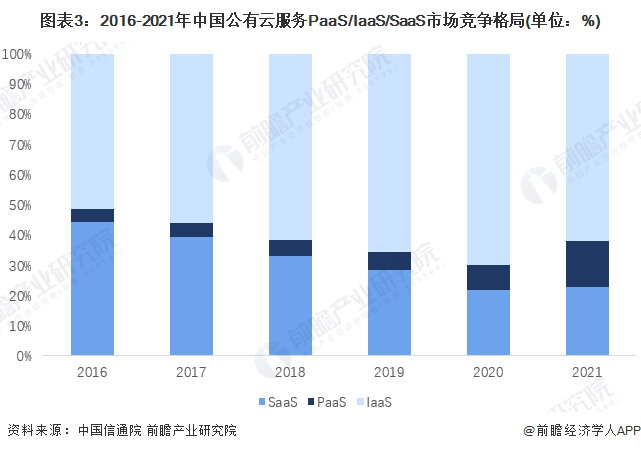
从云服务分类来看,目前IaaS的市场份额最大,2021年占比超过62.14%。但如今,IaaS产品的竞争其实也趋向于同质化,在这样的背景下,价格战成为IaaS产品竞争的主要方式。2020年6月,字节的火山引擎上市后就喊出了“极致性价比”的口号。
要打价格战,对于厂商来说,前提就是要降低成本。而自研芯片就是降低成本的成本的最好方式。
在国外,如亚马逊、谷歌等大厂,率先开始了通过芯片自研来降低成本。比如,自2015年亚马逊收购Annapurna开启芯片自研之路以来,AWS就先后历经了百余次降价。在国内,火山引擎总经理谭待也曾表示,实现极致性价比的方式就是“全栈自研、软硬一体”。
举个简单的例子,对于庞大的云服务器而言,电费其实占了日常运营成本的很大一部分,而决定电费的关键因素又在于服务器运行的功耗。
针对这个问题,阿里推出的首款通用型CPU“倚天710”采用的就是以低功耗为特点的ARM构架,并在设计上也采用了多核互联网和芯片间互联等低功耗技术。从阿里公布的数据来看,“倚天710”的能效比要比业界标杆提升50%以上。
去年底腾讯云与智慧事业群 CEO 汤道生在接受《中国企业家》采访时称,腾讯造芯的核心思路是基于自身需求,要么降低成本,要么更高效地使用基础设施。
整体而言,业内造芯的主要目的就是为了降本增效,尽管自研芯片的前期研发投入比较高,但在规模化投产后,单片成本一定比集中采购低。”一位同属互联网大厂芯片从业者向虎嗅解释。
除了大厂自研AI芯片之外,最近几年随着国内芯片半导体产业的蓬勃发展,也随之崛起了一大批的GPU芯片企业,比如芯原微电子、燧原科技、摩尔线程、壁仞科技等等。其中如老牌CPU厂商龙芯、海光更是都已经实现了上市。
不过,虽然业内人士也指出,计算芯片最大的门槛其实不是硬件,而是软件。如果一个芯片没有与之配套的软件生态,则很难真的形成大面积的应用。而这其实也是许多国内GPU公司的产品很难获得客户认可的原因。
但这两年,国内许多GPU芯片公司其实也在飞速成长,海光DCU8系列Z100产品数据接近英伟达的MI100产品,同时兼容CUDA生态而被市场广泛看好。
除此之外,国产GPU还面临更多挑战。比如之前产量的问题,虽然海光的芯片性能获得了市场的认可,但由于其出货量不足,以及其主要产能又供给给国家的超算中心,以至于市场上能拿到海光的芯片其实并不多。
另一方面也在于市场,在之前海外高端GPU芯片购买畅通的时候,国内芯片其实很难受到客户的认可,大家普遍的选择都是购买最先进、稳定的产品。而这一次国外先进的GPU受到限制之后,其实也在提醒国内的客户重新考虑外部的实际情况,从而也是给国产GPU企业进入客户供应链提供了一次机会。
认证为百度资深系统工程师的答主lychee在知乎提到,“之前有 30% 的性能提升可能都不会考虑(生态不行),现在有 30% 的性能差距可能都不是问题了,毕竟刀架在脖子上,先用上再说。”
除此之外,在摩尔定律“失效”的大背景下,世界芯片半导体亟需建立一套新的规则,这是中国芯片半导体前所未有的机会。
目前英伟达被限制的A100芯片采用的是7nm制程,之前华登国际合伙人王林在于光锥智能的交流中就提到:“未来5nm、3nm的制程工艺可能还存在一些困难,但7nm制程工艺突破只是时间问题。”
而超过7nm之后,制程工艺提升所带来的能效提升与为了达到这个制程所付出的成本就开始不成正比了。边际效益递减,企业投入重金研发先进制程的动力也开始不足。
早在2018年,国际芯片巨头格罗方德就宣布放弃7nm的研发,原因就是成本上升到无法承受的地步。而作为国际芯片代工巨头的台积电,最近也在3nm制程上也遇到了困难。
按照台积电的规划,3nm工艺的节点共有 N3、N3E、N3P、N3X 四种工艺。而目前市场却有消息,称因为成本太高,台积电也计划放弃第一代3nm工艺,转而投入到N3E的研发中。
与国外芯片半导体执着于更先进的制程不同,国内却已经开始在其他方面另辟蹊径,比如更先进的封装工艺,异构芯片等领域。而在这些方面,中国其实是有弯道超车的机会的,因为大家都在一个起跑线上。
在国内,壁仞科技的GPU芯片是率先采用Chiplet技术的芯片。
8月初,壁仞科技在上海发布了首款通用GPU BR100,该芯片集成了770亿个晶体管,其16位(半精度,英伟达最先进的芯片达到64位,双精度)浮点算力能达到1000T以上、8位定点算力能达到2000T以上,单芯片峰值算力达到了每秒千万次计算(PFLOPS)的级别。
虽然这款芯片只有半精度级别,但作为对比同样7nm制程的英伟达A100芯片在8位和16位定点的算力水平,壁仞科技的BR100已经超过了英伟达。
壁仞科技联合创始人、总裁徐凌杰表示,BR100系列芯片以及相应硬件计算产品将于今年年底量产。同时,壁仞科技也与包括浪潮信息在内的多家服务器厂商达成了合作。
所以说,虽然对我们来说,外部环境越来越严苛,但中国在芯片领域仍然在稳定的进步。给国内的企业一些时间,相信绝大部分问题都能够逐步有序的被解决。