模型层进入“平台期”的当下,小模型的出现,无疑为市场打开了新的可能。
大模型之战进入到今日,许多开发者都面临着一个共同的挑战:如何在保证高性能的同时,降低资源和算力的需求?
这一困境在端侧应用尤为明显,因为许多设备和应用场景对计算能力和存储空间有严格的限制。这无疑大大制约了大模型在各种设备和场景中的普及。
如何突破这一桎梏,实现性能与资源的完美平衡,从而打开潜在的市场?
近期,一些小型模型,如Mistral AI推出的Mixtral8x7B和微软发布的Phi-2,提供了一个可能的解决方案。
这些小模型在参数规模上相对较小,但在性能上却表现出了惊人的实力,甚至在某些方面超越了Llama2等规模更大的竞争对手。
而这也意味着,套在很多场景上的“参数枷锁”,也将有望被打破。一个新的增量市场,已经呼之欲出。
01 以小博大
从技术上说,Mistral 和Phi-2的特点就是一个词:短小精悍。
Mistral 8x7B由来自欧洲的Mistral AI打造,采用了稀疏混合专家模型(SMoE)技术,结合了多个针对特定任务训练的较小模型,提高了运行效率。

在许多基准测试中,Mistral 8x7B的性能已经达到甚至超越了规模是其25倍的Llama2 70B。
而微软推出的Phi-2虽然规模更小(仅27亿参数),但得益于“教科书质量”数据的训练,以及学习其他模型传递的洞见的技术,目前已在某些基准测试中超过了更大的模型,如 70亿参数的Mistral和130亿参数的Llama2。
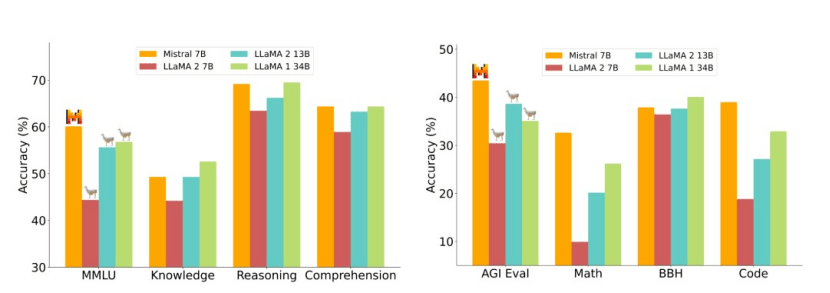
Mistral 7B在所有基准测试中超越了Llama2 13B
那么,这些异军突起的小模型,将会给已进入“平台期”的模型层,带来怎样新的想象?
具体来说,针对目前大模型的种种局限,小模型至少在两个方面实现了逆袭。
其中一个方面,就是其横向扩展了模型的使用范围,打开了之前因资源、算力而被束缚的市场。
以手机市场为例,根据Statista的数据,2021年全球智能手机用户数量已达到约39亿。
然而,小打开手机大模型的市场,却绝非易事。
由于手机设备上的内存和计算能力有限,为了平衡内存占用、执行速度和功耗,目前手机厂商普遍采用端云协同的解决方案,但这并非长远之计。
对于手机厂商来说,使用云端资源会产生额外的成本。随着用户规模的扩大,这些成本可能会不断增加,从而限制了其盈利规模的上限。
因此,最好的选择,就是能让手机在本地就能运行一款参数不大,但性能又能与云端大模型媲美的小模型。
同样地,在一些需要快速部署,实现实时响应的边缘场景,例如自动驾驶、物联网(IoT)中,实时决策和数据处理就显得至关重要。
根据ResearchAndMarkets的报告,全球自动驾驶汽车市场规模在2020年达到了约558亿美元。预计到2027年,这一数字将增长至约5,260亿美元。
目前的车载计算平台,如英伟达的DRIVE AGX Orin,计算能力是254 TOPS(每秒254万亿次操作),在高速公路等相对简单的场景中,由于数据量和计算复杂度较低,其算力并不是很吃紧。
然而,在更复杂的城市驾驶场景中,自动驾驶系统需要处理更多、更复杂的数据和任务,如实时检测和识别各种障碍物、预测其他道路用户的行为、规划安全路径等。
在这种情况下,有限的算力,就会限制自动驾驶的进一步普及。
Mistral和Phi-2这类小模型由于其较小的模型体积和较低的计算需求,可以在这些有限资源下高效运行。
因为车载系统需要在有限的能源和散热条件下运行,而较低的计算需求还有助于提高处理速度,实现实时决策和响应。
这一点对于推动自动驾驶和智能座舱技术的发展具有重要意义。
02 通向Agent之路
除了打通原先被限制的市场外,Mistral和Phi-2这类小模型的另一大逆袭之处,就是其与Agent的关系。
Mistral AI的CEO Arthur Mensch曾言:让模型变小一定会有助于Agents 的开发和应用。
而在模型层鲜有重大突破的今天,越来越多的人已经意识到:Agent就是大模型的未来。
对比AI与人类的交互模式,目前已从过去的嵌入式工具型AI(例如Siri)向助理型AI发展,目前的各类AI Copilot不再是机械地完成人类指令,而是可以自动化地完成各种人类工作流,
如果说Copilot这类生成式AI是“副驾驶”,那么Agent则可以算得上一个初级的“主驾驶”。
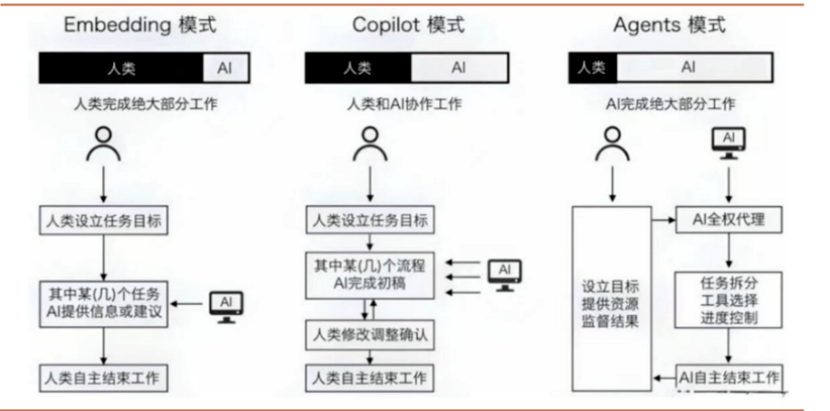
比尔·盖茨曾言:在计算行业中,平台是应用程序和服务构建的基础技术。Android、iOS 和Windows都是平台的例子。而Agent将成为下一个平台。
到了那时,要创建一个新的应用或服务,你不需要掌握编程或图形设计技能。Agent将能够帮助处理几乎所领域的事务。
那么Arthur Mensch为什么会断言小模型一定会有助于Agents的开发和应用?
这里主要有两个原因:一是推理成本,二是模型复杂度。
在推理成本方面,除了绝对数值外(即每1000个Token的成本),更重要的,是模型的推理预算与实际效能之比。
从目前的情况来看,Mixtral拥有46.7B的总参数量,但每个token只使用 12.9B参数,也就是说,Mixtral的实际执行速度和所需的成本和一个12.9B的模型相当。
下图展示了官方公布的模型生成质量与推理消耗成本的关系,与Llama2相比,Mistral7B和Mixtral8x7B表现出自己高能效的优势。
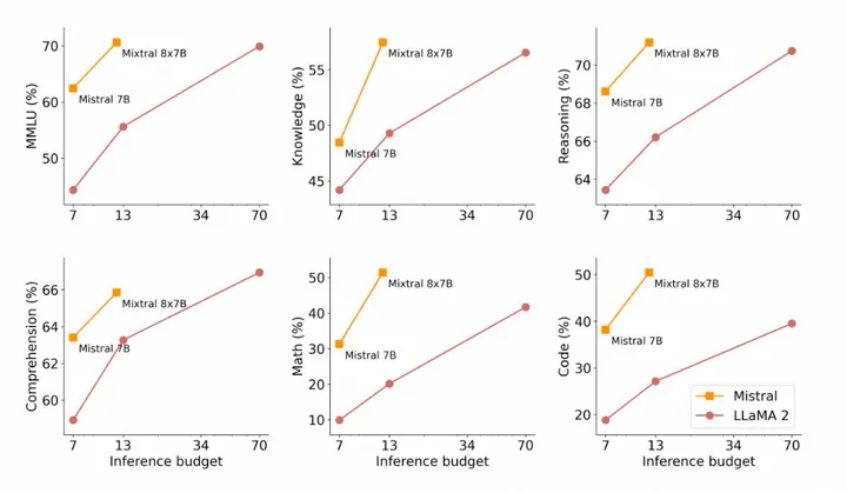
这意味着,与大模型相比,在保持高效能的情况下,Mixtral这类小模型通常需要更少的计算资源和时间来进行推理,因此更加适合用于实时交互和在线学习。
其次,小模型也有助于Agents的开发和应用,因为它们通常具有更低的模型复杂度,更容易被理解和调试。
Arthur Mensch对此谈到:当人们走向一个Agents和AI交互的世界,系统的复杂性也会因此大幅增加。这种高度复杂的情境可能导致崩溃(Collapse),即机器学习中的一种一切都停滞不前的状态,如果没有足够的自组织和解决问题的意愿,人们可能无法有效地应对和管理这些挑战。
为了解决这个问题,需要在设计和实现AI系统时充分考虑系统的可扩展性、模块化和可解释性。
而小模型通常具有更简单的结构和更少的参数,这使得具有更好的可调试性,从而便于让开发人员更容易理解和控制模型的性能,从而更快地将Agents推向市场。
03 新的胜出者
在模型层市场被少数头部企业左右的当下,小模型的出现,无疑为市场打开了新的可能。
从总的态势来说,之后的模型层竞争中,小模型可能会对大模型形成一种“农村包围城市”的态势。
“农村”象征着小模型主要占据的应用领域。这些领域通常包括资源受限的环境,如物联网设备、智能家居、移动设备和边缘计算场景。
在这些领域,小模型的灵活性、低成本和低能耗等特点使它们具有竞争优势。此外,小模型在定制化和迁移学习方面的优势,使它们能够更好地适应各种细分市场和特定任务。
“城市”则象征着大模型主要占据的应用领域。这些领域通常包括计算资源丰富、对性能要求较高的场景,如数据中心、云计算和高性能计算环境。

在这样的态势下,凭借着细分市场的优势,以及开源社区的协作和共创,小模型在性能上会不断迭代,并逐渐对大模型主导的领域形成一种“钳制”的优势。
这种关系,类似于农村为城市提供粮食等资源,维持城市的正常运行。在AI领域,大模型在特定领域的优化和提升,将愈发难以脱离小模型提供的实践场景和技术支持。
而面对这样的态势,头部的大模型企业,自然也不甘被钳制,因此,这些大厂可能的应对之策之一,是通过蒸馏(Distillation)或者合成数据(Synthetic data generation)等技术来训练出质量更高的小模型。
或者更简单粗暴一些,直接将小模型团队收购、兼并,为己所用。
在这样的情况下,未来小模型领域,怎样的企业更有可能胜出?
就大小模型的差异而言,小模型并不像大模型一样,需要庞大的算力、数据作为支撑,在这个领域,更考验的是对技术的理解,以及深厚的理论基础。
因此,将来在小模型领域,更有可能脱颖而出的团队,应该会是那些具有强大学术、技术背景,且一线研究者、技术人员具有更大话语权的企业。
例如这次的Mixtral的团队Mixtral AI, 就是由DeepMind和Meta的三位青年科学家建立。

联创三人,Arthur Mensch,CEO,前DeepMind研究科学家;Guillaume Lample,首席科学家,前Meta研究科学家,Llama项目带头;Timothee Lacroix,CTO,前Llama工程带头。
在创立Mistral前,Arthur Mensch在DeepMind任职,并主导了LLM、RAG、多模态三个领域最重要的论文,十分全能。
对一线研究者而言,唯有自由地践行自己的技术构想,在初期不过多地被资本干涉与左右,才更有可能做出亮眼的成果。
