现阶段的搜索AI,暂时还干不掉传统搜索引擎。
在传统搜索引擎的时代,想要找到某个问题的答案,你会怎么做?
也许你会打开你的浏览器,输入问题,然后点击搜索按钮。然后,你会看到一大堆的网页链接。
但除了某些十分简单、很显而易见的问题外,只要是稍微复杂些的,需要提炼的知识,人们往往都难以直接从搜索页面中获取答案。
于是,你不得不花费时间和精力去筛选和阅读这些网页,并不断点击“下一页”,才能找到你想要的信息。
也正因如此,在生成式AI的浪潮下,如微软的新必应、谷歌的bard、Perplexit AI推出的会话搜索引擎,都在试图解决人们的这一痛点。
而最近,这股AI搜索引擎的大战,也席卷到了国内。
几天前,昆仑万维推出了基于自身“天工”大模型的AI产品——天工AI搜索。可以说,这是目前第一款落地,并投入应用的独立AI搜索产品了。

该搜索AI一出,即刻在国内掀起了不小波澜,一些科技媒体纷纷盛赞,称其会“革了传统搜索引擎的命!”
那么,在表面的喧嚣之下,天工AI搜索,及其类似的一票AI搜索引擎,真正的现状究竟如何?
01 实际表现
鉴于到目前为止,关于天工AI搜索的测评,已着实不少了。因此,本篇文章不打算再重复测试某些千篇一律、无关痛痒的功能,而是打算针对大部分普通用户,在实际使用中最可能遇到的重点问题进行测评。
在这些重点中,最为人关切的,首先就是幻觉问题。
为了测试这点,我们分别将天工AI搜索与新必应进行了对比。


可以看到,在部分问题上,天工AI搜索与新必应都给出了较为准确的回答,没有出现幻觉/错误的情况。
但可以明显感到的是,天工AI搜索的答案比新必应要简略了许多。


例如,在“谷歌今年推出了哪些AI产品”这一问题下,天工AI只是笼统地提到了PaLM2这一产品。
而这很可能是天工AI的向量语义检索导致的。
这种检索方式的好处,是只需要计算向量之间的距离或相似度,而不需要对每个文本进行复杂的分析和处理。
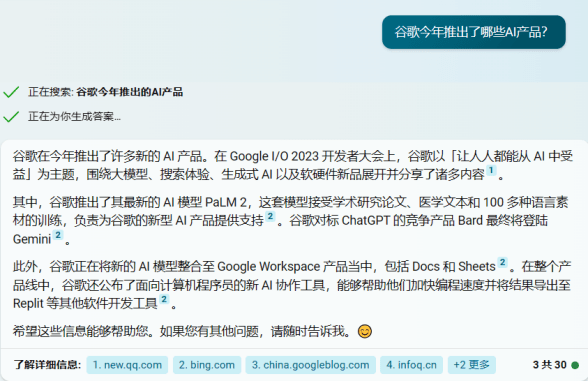
在新必应的精确模式下,AI的回应也很简略
通过对问题和潜在相关文档进行编码,并计算它们之间的相似度,天工AI就能有效地过滤掉无关或低质量的信息,只保留最相关和最有价值的信息。
但这样一来,生成的内容就会变得十分简略。
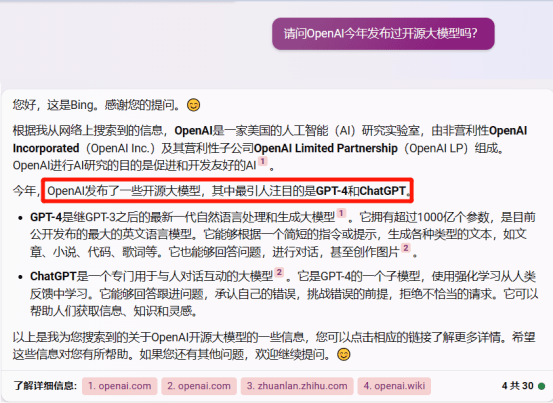
可即便采用了向量语义检索,也难以完全避免幻觉问题。
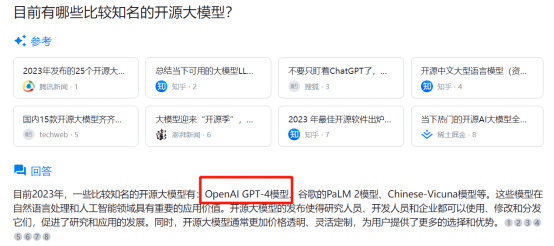
在这个回答中,天工AI犯了一个明显的错误。众所周知,在目前OpenAI的计划中,GPT-4是不开源的。
而同样的,类似的错误与幻觉也出现在了新必应中。
从理论上来说,如果搜索AI能够从网络上爬取到所有的信息,并且能够完美地理解和处理这些信息,那么它就不会产生幻觉或错误。但是,这在实际中是很难实现的。
至于具体的原因,暂时先留到文章第二部分解释。
在这里,我们先看看另一大使用搜索AI时的重点:理解和分析能力。
从功能上来说,AI搜索这个新物种,之所以被人们寄予了厚望,是因为自从其诞生的那天起,人们就不单单只想将其作为一个纯粹的搜索工具,而是希望它成为一个能集知识的发现、处理、分析和重新组织为一身的个人智能助理。
毕竟,在这个信息密度倍增的时代,人们已经越来越不满足于接收那些未经“咀嚼”和“消化”的原始信息了。

那么在这方面,天工AI搜索表现得怎样呢?
我们可以用几个比较考验分析和理解能力的问题对其进行测试。
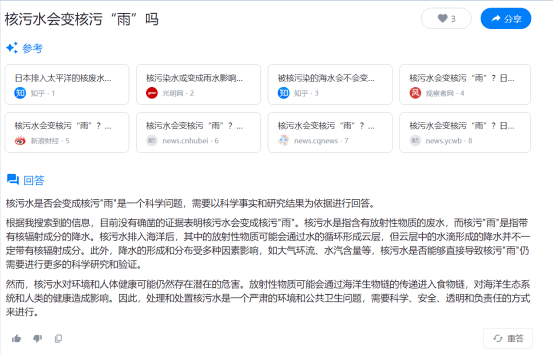
从这个回答,可以看出天工AI仍然保持了十分严谨的风格,对“核污水是否会变核污“雨”没有给出一个轻率的结论。
然而,这样的回答,仍然停留在了一个“知其然”的层面,在对某些复杂问题进行询问时,人们更渴望搜索AI展现出更智能、更具主观能动性的一面。

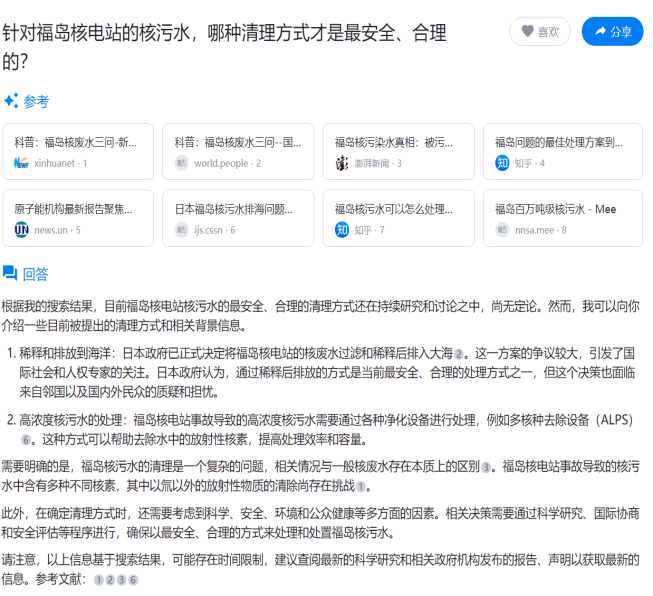
在这个问题上,新必应的回答,则显得详细和深入得多。
而要想实现这样的回答,就不能仅仅只对网页中的信息、数据进行简单的搜集,而是要依靠AI自身的智能,对其进行提炼、分析和理解。
而这样的智能,在面对一些需要选择和比较的问题时,就显得尤为重要。

在某种程度上,AI搜索引擎迈向智能助理的第一步,就是对问题形成自己的“看法”。
只有这样经过深度处理后的信息,才能更有效地帮助人们进行思考、决策。
而这样具有“主动性”的特点,正是新一代AI搜索引擎区别于传统搜索引擎最本质的区别。
02 人工智能VS传统搜索
有了AI加成的搜索引擎,究竟能否战胜传统的搜索方式?
自从今年新必应问世以来,这就是一个备受关注的话题,然而,最终的数据却无情地表明了:现阶段的搜索AI,暂时还干不掉传统搜索引擎。
分析公司StatCounter的数据显示,今年7月份,必应在全球的市场份额为3%。这一份额与今年1月(新必应推出前一个月)的基本相同。
分析公司Similarweb的另一份报告显示,7月份必应的月访问量约为谷歌的1%,也与1月份大致相同。
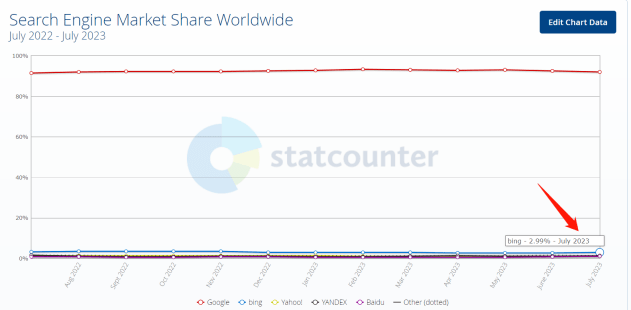
全球搜索引擎市场份额,来源:StatCounter
尽管这样的数据,并没有对所有直接访问必应聊天页面的人进行统计,但它仍印证了传统搜索引擎的地位。
这样的现实,说明了在新式的搜索AI推出许久之后,人们仍然不愿舍弃传统搜索方式。
而这背后的原因,其实也很简单:可靠性。
对很多人来说,用谷歌、百度搜索,虽然麻烦一点,但找到的内容足以让自己的材料有足够高的可信度。
而如果使用AI搜索,哪怕所有的答案中,只有5%是幻觉和错误,就足以让人在进行决策和判断时翻车。
并且从技术环节上来说,联网功能也并非根除幻觉的“灵丹妙药”。
这主要是因为,网络上的信息包含了很多噪声,这些噪声往往是一些不完整、不一致、不可靠的信息。
而搜索AI在识别和过滤噪声方面的限制,是由多个技术环节共同造成的,这其中包括了网页抓取、索引构建、链接分析等。而从这些噪音中,提取出有价值和意义的信息却绝非易事。
因为在这一过程中,链接的稀疏性、不均匀性,网页的多样化,都有可能影响搜索AI判断,导致噪声的干扰。
既然如此,那这是否意味着,搜索AI始终无法撼动传统搜索引擎的地位呢?
其实不然,因为一项新技术的前景,有时不在于其在原有赛道表现如何,而在于其是否能开辟新的赛道。
如上一部分所述,在这个信息密度倍增的时代,未经处理的原始信息,已经很难满足人们的认知需求。
换句话说,在这个时代,人们想要的不仅是信息、知识,而是智慧。
在目前新必应等搜索AI的应用场景中,最有价值,也最不可或缺的部分,就是其对某些晦涩、艰深内容的解读。
有时候,只要使用了正确的提示词,搜索AI就能将信息中难以理解的部分,转化为简明易懂的内容,
而这无疑大大地降低了个人的认知和理解成本。
从这个角度上说,搜索AI有着传统搜索引擎无法取代的意义。
因为其不仅仅是简单地将信息摆在人们面前,并且还提供了一种见解、思路和策略,而这正是真正的个人智能助理所必备的特质。
正如现在的某些浏览器,都会自带“翻译插件”,方便人们在浏览外文网站时,能够高效率地理解其中的内容一样,或许在未来,搜索AI也会以类似的形式,在人们阅读网页时,一边进行总结,一边提供思路,见解。
到了那时,人们甚至能要求其对网页中的具体的某段文字,进行分析和总结。
03 未来的搜索引擎
按照上面的思路,未来的搜索引擎,也许将是结合了传统搜索与AI搜索二者优势的产物。
其最有可能的技术思路,则很可能类似于当下的AI智能体。
具体来说,在获取信息时,搜索AI可以先借助传统搜索引擎,爬取大量网页,之后将这些庞大的,未经处理的信息,交由一位智能体专门进行筛选、提炼。
之后,这些经过提炼后的信息,会交由一个负责审核和纠错的智能体,以核验信息的准确性。
当确认无误后,这些信息最终将交由负责整理和输出的智能体,并通过其分析、推理能力,为人们提供有价值的思路、建议。

实际上,这样的技术路线,在现实中并不遥远,并且已经被某些团队投入了使用。
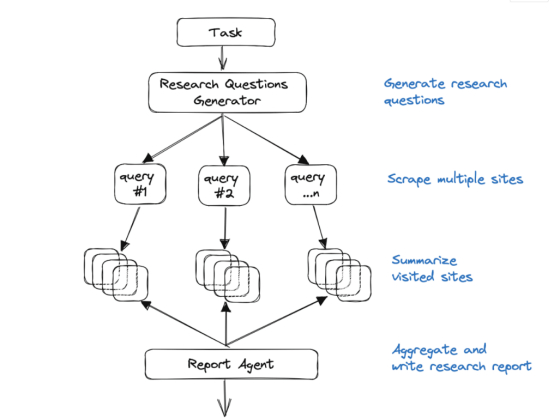
例如,最近一个由哥大研究人员开发,名为GPT Researcher的AI智能体项目,已经能独立完成各种类型的网络科研任务。
其主要原理是运行「规划者」和「执行者」智能体。
其中规划者生成研究问题,并提出针对该问题的一系列大纲、要领。
之后,执行者会针对大纲中的每个子问题,汇总20多个网络来源,形成客观、真实的结论。
这样的解决方案,避免了以往的AI+联网搜索时,因为获取的资源有限,以及内容的无规划性,可能导致肤浅的结论或带有幻觉的答案。
在可以预见的将来,倘若类似的技术,用在了AI搜索上,那么人们就可以既能借助传统搜索引擎的准确性,以及AI搜索的智能分析能力,极大地降低个人的认知成本,并以此将其作为每个人都能拥有智能个人助理。
