忽如一夜春风来,湖仓架构似花开。
今年的云计算市场,似乎谁不提湖仓架构谁就落伍。为何湖仓架构这么火?如今看来,数据湖和数据仓库加速互动,看似偶然、其实必然。
曾几何时,很多用户因为本地数据仓库方案各种局限性而叫苦不迭;当进入到大数据时代,数据湖概念兴起,人们看到了实现数据价值的新途径,甚至还有厂商发出用数据湖替代传统数据仓库功能的声音。
殊不知,数据湖与数据仓库从来就不是取代与被取代的关系。在数据湖蓬勃发展的同时,数据仓库借着云计算的东风,同样在高速成长与进化。尤其是当我们践行大数据十余载、数据价值逐渐深入人心之时,蓦然回首愈发明白:数据只有打通、流动、共享才能充分发挥其价值。
这也是以亚马逊云科技Lake House为代表的智能湖仓架构近年来广受用户青睐的原因。数据湖与数据仓库既不是非此即彼的二元选择,也不是永不相交的两条平行线,无缝流动、彼此补充才是二者最佳归宿,也是加速挖掘数据价值的唯一途径。
从亚马逊云科技Lake House智能湖仓架构,我们真正读懂了实现数据价值的未来。
众所周知,数据已然成为一种关键的生产资料,成为数字化时代一切运转的基础。大量基于数据驱动的业务场景涌现,加速重塑企业与组织的生产、经营、销售、服务等业务。
以银行营销为例,过去更多依赖本地部署的数据仓库解决方案来制定营销方案,数据模型范式有要求、维度单一、实时性差,导致营销方案分析维度少、业务响应差,颇像“事后诸葛亮”;而如今的银行营销方案,通常构建在基于数据驱动的场景之上,会收集用户各种维度的相关数据,采用机器学习不断学习训练模型,实现在合适场景、合适时机将合适产品推荐给用户,并形成数据价值闭环,不断完善模型,实时调整营销策略,实现银行与用户的双赢。

一个小小的营销场景恰恰反映出数据湖核心价值所在。自2010年Pentaho CTO James Dixon首次提出数据湖概念以来,数据湖之所以迅速被人们所认可,核心原因在于它帮助用户梳理清楚从数据存储、数据汇聚到数据挖掘的过程,这恰恰是大数据时代下实现数据价值的关键基础。
大数据时代,海量规模、类型丰富的数据每时每刻都在产生,而数据湖作为一个以原始格式存储数据的系统,按原样存储数据,无需事先对数据进行结构化处理,可以存储结构化数据、非结构化数据以及二进制数据等,并进行数据拉通、消除数据孤岛,为数据分析、机器学习等提供极大便利。
数据湖概念深入人心,但数据湖落地却并不是一帆风顺,这十年以来各类代表厂商、营销理念、解决方案层出不穷,失败案例也不在少数,而近年来真正“拨乱反正”、率先走出数据湖价值落地之路则是以亚马逊云科技为代表的云服务提供商们。
归根结底,云计算的弹性、可扩展性、存算分离等特性,使之与数据湖不期而遇时,在技术层面和使用层面高度契合,成就了实现数据价值的一段佳话。
云计算与数据湖之所以能成为一对绝佳的CP,数据规模是关键因素。
看一个直观例子,OpenAI GPT-1模型参数只有1.1亿个,预训练数据量为5GB,最新的GPT-3模型参数则高达1750亿个,预训练数据量高达45TB,模型规模和数据量增长了千倍,更何况那些基于AI模型的各种智能应用每天所产生的海量数据。
基于数据驱动的智慧应用爆发,带来PB级甚至EB级的海量规模数据时,云计算与数据湖组合带来的价值愈发凸显:当数据规模越来越大时,计算能力成为关键,而有了云计算的弹性与可扩展,可以让海量数据的存储与分析更加容易;与此同时,云计算与数据湖都广泛采用分布式架构与开源体系,技术迭代与进化得以加速,适应未来数据处理的新需求与新变化;另外,在云上构建起数据湖平台之后,天然集成更多新技术与服务,例如更好支撑起机器学习等人工智能技术,实现云数智的融合。
因此,虽然开源和存储厂商是数据湖概念的先行者,但真正走出落地之路则是以亚马逊云科技为代表的云服务商。
以亚马逊云科技为例,早在2009年就推出了 Amazon Elastic MapReduce(EMR)架构,实现跨 EC2 实例集群自动配置 HDFS;2012年,亚马逊云科技推出了具有标志性意义的云数据库仓库服务Amazon RedShift;随后,亚马逊云科技陆续打造出Athena、Glue、Lake Formation等一系列核心产品,逐渐形成完整的数据湖解决方案。

亚马逊作为全球最大的互联网公司,其数据规模、数据复杂度、数据处理难度、数据价值挖掘在业界无出其右,这使得亚马逊云科技对于数据湖的理解、使用以及产品打造等方面往往极具借鉴价值。
例如,数据湖构建的核心目的是为了数据分析与数据挖掘,因此快捷的交互式查询就至关重要。以Amazon Athena为例,其简单易用,采用标准SQL 分析 Amazon S3 中的数据,只需指向开发者存储在 S3 中的数据,定义架构即可开始查询,它无需执行复杂的ETL作业来为数据分析做好准备。
而数据湖无需事先对数据进行结构化处理,可以按照任何格式存储数据,带来最大的挑战之一就是查找数据并了解数据结构和格式,此时数据目录和ETL服务就至关重要。以Amazon Glue 服务为例,其核心解决思路就是为用户建立起无服务器架构的数据目录和ETL服务,无需用户自己写ETL管道,快速完成数据的抽取、转换和加载。
此外,构建和使用数据湖并不是一件轻松的事情,随着海量数据规模的不断增加,数据湖的建立、配置、管理和使用的复杂性也会随之增加,很多用户对于加载数据源、设置分区、定义转换作业等复杂手动任务更是深恶痛绝。
此时,云计算的优势再一次凸显出来。以Amazon Lake Formation为例,开发者只需手动定义数据源,制定要应用的数据访问和安全策略,Lake Formation 会自动帮助开发者从数据库和对象存储中收集并按目录分类数据,再将数据移动到新的Amazon S3 数据湖,大幅缩短数据湖的构建时间。
可以说,数据湖已经不仅仅是一个概念,更代表着过去十年用户实现数据价值的一种进化。在这个过程中,云计算凭借着弹性、可扩展、灵活的特性,不断屏蔽数据湖从建立到使用过程中的各种复杂性,降低数据湖的使用门槛,加速实现数据价值的落地。
但这就足够了么?
2020年是一个重要的分水岭,全球疫情常态化以及错综复杂的内外部环境,使得企业无时无刻都面临着不确定性,数字化时代的敏捷性和全局视角洞察能力正变得愈发重要,而数据的打通、流动与共享无疑是构建起敏捷性和全局视角洞察能力的关键所在。
换句话说,数据湖、数据仓库以及其他数据存储方案并不是彼此割裂,而是需要无缝协同工作,让数据自由流动、共享与使用,让基于数据的决策更加科学与精准。尤其考虑到海量数据规模成为常态的大背景下,无论是数据湖、数据仓库还是其他数据存储方案,其所存储的数据量一直在不断膨胀,逐渐衍生出一种新的现象:即数据往来、移动操作变得愈加复杂与困难。
亚马逊云科技将这种现象形象地比喻为“数据重力”。毫无疑问,“数据重力”是实现数据价值的最后壁垒。要想打破壁垒,Amazon Lake House智能湖仓架构来围绕数据湖构建起专用数据闭环,实现以安全且受控的方式在不同数据存储方案之间快速移动数据。
事实上,亚马逊云科技很早就致力于消除数据重力现象。早在Amazon Redshift诞生伊始,就允许从数据湖S3中导入数据进行分析,并且在2017年推出Redshift Spectrum引擎,打通数据仓库对数据湖中数据的直接访问;之后,2019年,亚马逊云科技将redshift spectrum 引擎命名为Lake House引擎;到2020年re:Invent大会上,亚马逊云科技提出Lake House智能湖仓架构。
Lake House智能湖仓架构关键之处在于以高度扩展的数据湖为核心,构建起专用数据闭环,实现以安全且受控的方式在不同数据存储方案之间快速移动数据, 为不同业务场景专门构建的分析工具或数据存储之间无缝的协同工作(例如:数据仓库、搜索引擎、机器学习平台等)。
现实需求情况的确如此如此,例如,用户有时希望将来自Web应用程序的点击流数据直接收集在数据湖内,并将其中部分数据移至数据仓库以生成每日报告;用户有时又希望将特定区域内的产品销售查询结果从数据仓库复制到数据湖内,进而使用机器学习对大规模数据集运行产品推荐算法。
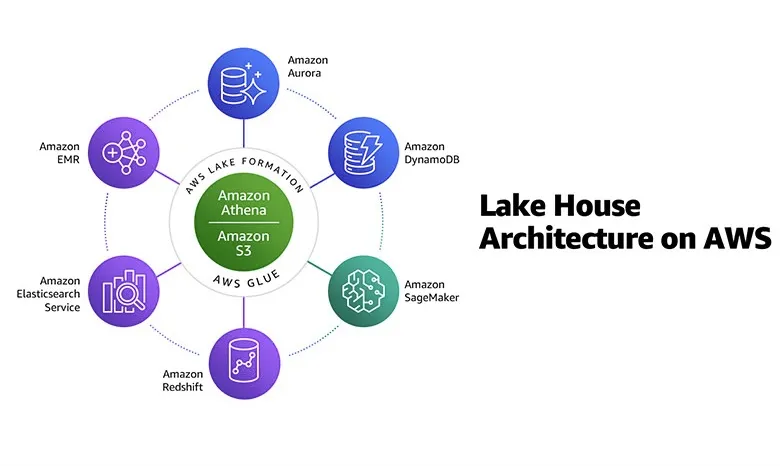
随着亚马逊云科技在2020年Re: Invent上公布一系列新功能,Lake House架构逐步形成五大特征:可扩展数据湖、专门构建的(Purpose-built)分析服务、无缝数据移动、统一数据治理、出色的性能与成本效益。
以无缝数据移动为例,亚马逊云科技的无服务器数据集成服务Glue已经日臻成熟,提供数据集成所需要的全部功能,自动发现数据并存储Schema,与亚马逊云科技上运行的Aurora、RDS、RedShift、S3和数据库引擎天然集成。通过Glue elastic view, 开发人员使用PartiQL即可在多种数据库及数据存储方案内创建物化视图,几分钟就能完成跨数据存储方案的数据合并与复制。
又如,在当今海量数据规模的环境中,对于数据访问活动的授权、管理和审计等一系列治理至关重要。例如,如何实现跨组织内各类数据存储方案的安全管理、访问控制与审计跟踪,往往因为极其复杂和耗时让用户捉襟见肘。面对这种情况,Lake House架构凭借集中访问控制与策略,辅以列与行层级的过滤等功能,带来细粒度访问控制与治理选项,能够立足单一控制点对跨数据湖及专用数据存储系统的访问行为进行全面管理。
综合来看,随着基于数据驱动的智慧应用遍地开花,用户面临的将是一个数据规模更加庞大、管理更加复杂的数据环境。面向未来,数据湖、数据仓库以及专用分析引擎的协同运行会更加频繁,智能湖仓架构必然会成为用户们的首选,而Amazon Lake House无疑将迎来更大的价值舞台。
