“过去会区分核心数据和非核心数据。现在是所有数据都很重要,所有数据都不能丢失。”去年武汉一家大型三甲医院信息中心主任接受笔者采访的观点依然让人记忆犹新。
无独有偶,在产业数字化和数字产业化的双轮驱动下,一个海量数据时代正加速到来。IDC《数据时代2025》白皮书就预测,到2025年全球数据量总和将达到175ZB;其中,来自中国的数据量预计未来五年年平均增长30%,并且到2025年将成为全球数据量最大的区域。
海量数据时代来临,一方面为企业拥抱数字化、洞悉市场规律、挖掘数据价值提供了充分条件;另一方面,海量数据的存储、备份、恢复等也给传统备份方式、产品带来了前所未有的挑战。正如爱数公司所认为,数据大爆炸让数据备不完、存不下、管理难愈发成为各行各业的新常态,而基于分布式架构的备份系统,正是应对海量数据备份恢复挑战的那一副良剂。
海量数据的产生离不开外部政策的强力导向和企业数字化转型的内部强大驱动力。
以中国市场为例,《中国数字经济发展白皮书(2020)》透露,数字经济近年来成为经济发展的又一引擎,其GDP占比逐年提升,在数字经济的推动下,各行各业的数字化转型明显提速;而刚刚出炉的《十四五规划》报告中,更是强调提升数字产业经济占比的核心目标,全面推动建设数字中国和发展数字经济。
同样,海量数据的产生也离不开企业数字化转型强大的内部驱动力。尤其是随着数字化转型进入到深水区,云计算、大数据、AI等数字化技术加速在业务场景中落地,极大地产生了丰富的数据。
那么,与过去相比,如何理解当前海量数据的规模?
用几个简单的数据来形象说明。例如,一家中型科技公司的开发测试环境往往达到上万个虚拟机主机;交通、智慧城市等场景一年往往能产生超过10PB规模的数据量;银行、保险等金融机构拥有超亿个小文件……

各个行业用户明显感觉到数据量爆炸性的增长。“面对海量数据,越来越多用户存在备不完、存不下、管理难的情况。”爱数AnyBackup产品副总裁常华如是说。
具体来看,首先是用户的数据总量呈现出指数级的增长趋势,完全备份几乎无法完成,哪怕用户,精打细算、调优海量备份任务的计划调度,依然有触碰到红线的风险;其次,采用传统备份架构体系,往往存在着N套备份系统对应N*N个备份客户端的情况,使得管理备份任务变得异常复杂;最后,随着数字化程度越来越高,用户生产数据增速越来越快,但是规定的备份时间窗口没有变,使得备份窗口压力极大。
“传统备份解决方案通常是采用串联、堆叠的部署方式,现在已经很难适用海量数据的保护了。”常华表示道,“解决之道就是分布式架构,通过分布式架构的易扩展、高吞吐和高可用,来实现海量数据备份恢复的以快制胜。”
在数据保护领域采用分布式架构乃是顺势而为,顺应了海量数据时代数据保护需求的变化。
分布式架构本身并不稀奇,之前在IT各个领域都有着广泛的应用。那么,分布式架构应用在数据保护领域有哪些独特之处,它又是如何实现易扩展、高吞吐和高可用来解决海量数据备份恢复的挑战?
以爱数AnyBackup Family 7分布式架构为例,之所以能实现易扩展、高吞吐和高可用,不仅仅是其采用了Scale-Out横向扩展架构,还在于其完成了从客户端到底层备份介质端到端的优化,针对备份恢复的每一个环节进行有针对性的优化,从局部到整体完成与分布式架构的适配、调优。
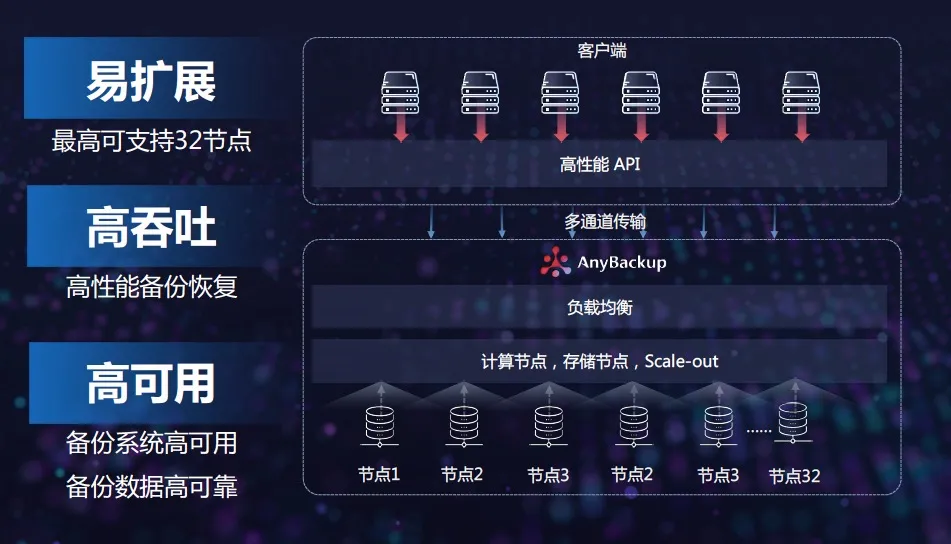
例如,在客户端,针对虚拟化、数据库、云平台等工作负载,爱数提供了专有API,结合各种调优算法,来实现海量备份性能的提升;又如,通过负载均衡,对于备份任务和备份容量进行多任务分发和合理分配,以达到一个整体最优的性能。
“在六节点集群吞吐量测试报告中,备份吞吐率达到36TB/h,恢复吞吐率达到20TB/h。”常华透露,“爱数AnyBackup Family 7分布式架构今年将实现单套备份系统最高支持32个节点,存储池容量超过10PB。”
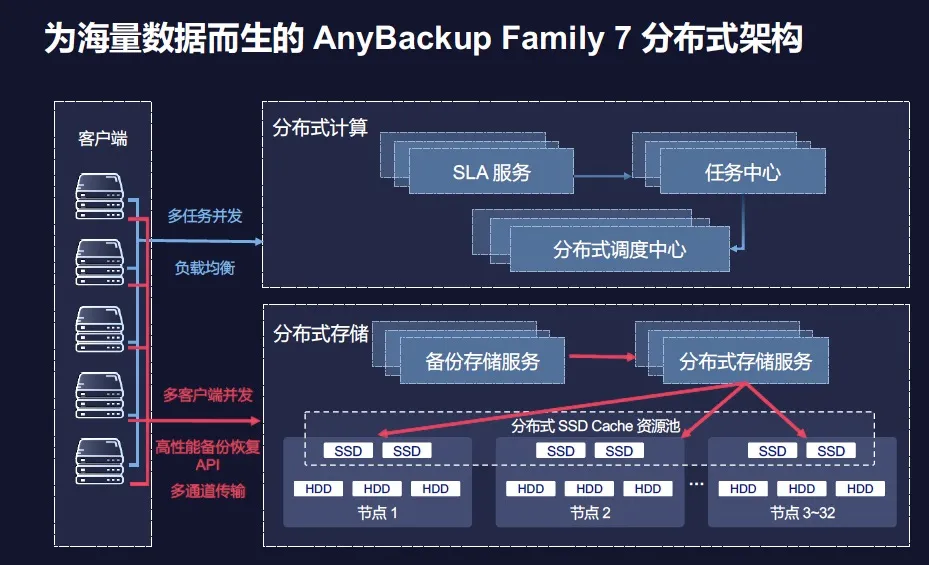
另外,存算分离架构也是爱数AnyBackup Family 7分布式架构的一大核心特征。存算分离架构的一大好处就是具有足够的灵活性,当用户规模越来越大之后,其对于灵活性要求也会提升,往往需要根据业务或者工作负载的需求来灵活扩展计算或者存储,如果采用计算与存储紧耦合的方式,计算与存储扩缩容则极为不方便,无法满足用户业务对于灵活性的需求。
以爱数AnyBackup Family 7分布式架构为例,在其存算分离架构之中,分布式计算主要负责海量任务并发和负载均衡,完成各种任务的调度、匹配与优化;而分布式存储则通过多通道的并发和数据负载均衡,将接受过来的数据写入到备份节点之中。
“存算分离架构,可以最大限度来提升备份与恢复的每个工作环节。”爱数AnyBackup研发副总裁邓平介绍道,“例如,分布式的SLA策略调度,针对保护任务、保护对象,采取不同的备份策略和周期。”
事实上,采用分布式架构的备份产品在实际业务场景中已经凸显出其优势。以某省政务云平台为例,其云主机的数据量已经达到1520TB,数据库的数据量则达到了1641TB,整个平台有数千个任务,并且依然保持着很高的增长速度,其每个备份域只需要部署一套备份系统即可完成日常的备份作业,所有39个节点通过一套运营管理产品就实现了全平台的管理,极大简化了日常管理工作。
哈佛大学管理学教授克里斯坦森在《创新者的窘境》中认为,创新关键不仅仅在于技术进步或者科学发现,更加关键的是在于对市场需求变迁的主动响应。
毫无疑问,海量数据时代,用户对于备份恢复的需求变化就是“快”,在时间窗口有限的情况下完成对于不断增长的海量数据的备份、管理与恢复。
这种趋势直接驱动着以爱数为代表的公司将分布式架构创新应用在备份产品之上,并且以全局的视角,以及着眼于备份恢复每一个环节的优化,来实现“快”这个目标。
面向未来,“快”始终是数据备份恢复的核心目标,分布式架构在数据保护领域的创新还会有巨大的空间,以真正实现海量数据的有备无患。
