在2012年的ImageNet挑战赛(ILSVRC)上,深度卷积神经网络AlexNet横空出世,在图像分类识别领域实现了质的飞跃,被认为是AI时代的标志性事件,代表着深度学习时代的正式开端。
在此之前,深度学习“如何出圈”的一大挑战,就是深度神经网络训练面临算力不足的难题。而让AlexNet实现算力突破的关键,就在于当时研究者使用了英伟达的GPU。
GPU一战成名,成为伴随AI技术一同进化的基础设施。英伟达也同时抓住了AI计算的新增长机遇。随着AI算力要求的爆炸式增长,英伟达GPU产品系列也经历了多轮的升级。
现在,英伟达的GPU家族又迎来一次 “史上最大”的性能升级。而此次升级距离上一次发布“地表最强AI芯片”Tesla V100已经过去三年。
三年蛰伏,一鸣惊人。

(NVIDIA A100 GPU)
英伟达首次推出第8代安培GPU架构,以及首款基于安培架构的NVIDIA A100 GPU,采用7nm工艺,在和上一代Volta架构V100 GPU几乎相同面积的晶圆上放置了超过540亿个晶体管,晶体管数量增长了2.5倍,但尺寸却仅大了1.3%,而在AI训练和推理算力上,均较上一代Volta架构提升20倍,HPC性能提升到上一代的2.5倍。
A100 GPU的独特之处在于,作为一个端到端机器学习加速器,第一次在一个平台上面统一了AI训练和推理,同时也将作为数据分析、科学计算和云图形设计等通用工作负载的加速器。简单来说A100 GPU就是为数据中心而生的。
在A100 GPU的基础上,英伟达同时发布了全球最强AI和HPC服务器平台——HGX A100,全球最先进的AI系统——DGX A100系统,以及由140个DGX A100系统组成的DGX SuperPOD集群。此外,还有涉及智能网卡、边缘AI服务器、自动驾驶平台合作以及一系列软件层面的平台型产品的发布。
可以说,英伟达这次不是放出一颗“核弹”,而是一个“核弹集群”,还是饱和攻击的那种。英伟达从云端到边缘再到端侧,从硬件到软件再到开源生态,几乎建立起一个坚不可摧的AI计算的壁垒,同时也将AI芯片的竞争带上了一个小玩家难以企及的高度。
英伟达的AI服务器芯片业务正在发生哪些新变化?A100 GPU的发布,对于AI服务器芯片市场有哪些影响,以及对于云计算市场带来哪些变化?这成为我们在“看热闹”之余,要重点探讨的几个问题。
AI服务器芯片:英伟达AI计算增长新极点
众所周知,游戏、数据中心、专业视觉化以及自动驾驶等新兴业务是英伟达的四大核心业务板块。其中,游戏业务虽仍然是营收的支柱板块,但是受到PC游戏市场趋于饱和并向移动端转移的影响,独显业务的比重正在逐步缩小;专业视觉化业务一直为英伟达贡献着稳定营收,但受其他业务增长的影响,业务占比也在持续下滑;自动驾驶等新兴业务板块,目前只占整体应收的很小部分,且增速有限,但可以看作是英伟达未来的长线市场。
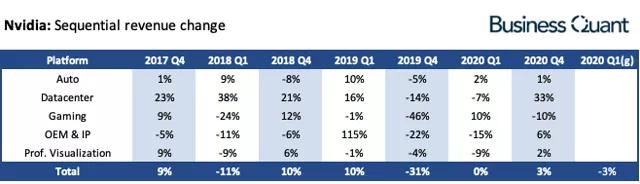
(Nvidia: Sequential Revenue Change)
最明显的则是英特尔在数据中心业务板块的增长。近几年中其营收大部分时间处于高速增长状态,且营收占比逐步靠近游戏业务。
根据英伟达最新的2020财年Q4财报数据显示,”游戏“收入高达14.9亿美元,约占总营收的47%;而增长强劲的数据中心板块,AI服务器芯片的营收达到9.68亿美元,同比增长了42.6%,,逼近10亿美元大关,远远超出市场预期的8.29亿美元。
整体上,随着全球数据中心,特别是超大型数据中心,对AI芯片需求的加速扩张,英伟达的AI服务器芯片也迎来了高速增长,正在跃升为英伟达最具有市场拓展潜力的业务分支。
从业务增长的前景上看,英伟达推出A100 GPU服务器芯片以及AI系统集群,所要把守住的正是在当前数据中心中AI服务器市场的霸主地位。
那么,英伟达正在如何构建这一AI服务器芯片的产品体系呢?
一般来说,对于深度神经网络算法模型,其模型框架的训练需要涉及非常庞大的数据计算,但运算方法要求又相对简单,所以需要在云端进行大量高并行、高效率和高数据传输的运算。因此相较于擅长复杂逻辑运算、但核心数较少的CPU,拥有多个计算单元的GPU更适合于进行深度神经网络的训练任务。
这是英伟达的GPU在全球云端AI服务器芯片市场,尤其是训练端,赢得市场先机的根本原因。与此同时,英伟达针对一系列AI服务开发的完备的TESLA GPU产品线以及成功布局针对GPU的“CUDA”开发平台,才是英伟达在AI服务器芯片市场一家独大的主要原因。
从2016年推出第一个专为深度学习优化的Pascal GPU,到2017年又推出性能相比Pascal提升5倍的新GPU架构Volta,再到现在推出比Volta性能高20倍的Ampere(安培)架构,英伟达在数据中心的GPU产品一直成功实现高速且稳定的性能提升。
此外,英伟达推出了神经网络推理加速器TensorRT,可以为深度学习应用提供低延迟、高吞吐率的部署推理加速,兼容目前几乎所有主流的深度学习框架,使其能够满足超大数据中心从AI训练到部署推理的完整的AI构建。
而在去年3月,英伟达宣布以68亿美金收购了以色列网络通信芯片公司Mellanox。通过对Mellanox的加速网络平台的整合,英伟达可以解决通过智能网络结构连接大量快速计算节点,以形成巨大的数据中心规模计算引擎的整体架构。
就在发布A100 GPU的同时,英伟达也基于Mellanox技术,推出全球第一款高度安全、高效的25G/50G以太智能网卡SmartNIC,将广泛应用于大型云计算数据中心,大幅优化网络及存储的工作负载,实现AI计算的更高安全性和网络连接效能。
当然,收购Mellanox的意义不止于此,除了解决高性能的网络连接和算力输出问题,英伟达还将也拥有GPU、SoC、NPU面向不同细分领域的三大处理器,这意味着英伟达已基本具备了独立打造 AI 数据中心的能力。
整体上,随着云端数据中心正在从传统的数据存储向着进行深度学习、高性能计算(HPC)和大数据分析的方向演变,英伟达也将在其中扮演着更加重要的AI计算服务商的角色。
跨越英伟达的坚壁高墙,AI计算竞赛加剧
当然,云端AI服务器芯片市场还远未到格局已定的地步,反而在2019年迎来最激烈的竞争态势。
英伟达的GPU产品,因其高耗能和高价格一直制约着云计算数据中心的AI算力的成本。从服务器芯片市场的另一位大佬英特尔,到AMD、高通,云计算服务商亚马逊、谷歌、阿里、华为以及众多新兴的AI芯片创业公司,都在积极投入云端AI服务器芯片的研发,寻求替代GPU的解决方案。可见天下苦“GPU”久矣。
在2019年,相比英伟达的略显沉寂,其他各家则纷纷推出了自己的AI服务器芯片产品。比如去年上半年,英特尔、亚马逊、Facebook以及高通都陆续推出或宣布推出自己的专用AI服务器芯片,试图在AI推理运算上实现对GPU和FPGA的替代。年中,我国的主要云端AI厂商也集体发力,寒武纪在6月宣布推出第二代云端AI芯片思云270;8月,华为正式发布算力最强的AI处理器Ascend910及全场景AI计算框架MindSpore;9月,阿里推出当时号称全球最强的AI推理芯片含光800,基本都在对标英伟达的T4系列产品。

在所有AI芯片的竞争者中,作为第二名的英特尔显然是最想挑战英伟达的霸主位置,也是最有可能挑战英伟达的代表。
作为通用服务器芯片的传统巨头,英特尔最有可能的策略就是把GPU和AI都融入到自己的CISC指令集和CPU生态中,也就是把CPU和GPU部署在一起,云服务商们只需购买一家的产品,就能更好地发挥AI计算的效能。
在All IN AI的英特尔那里,他们是如何来构建这一AI计算策略的?
英特尔最先补足的就是AI硬件平台版图,而收购则是最快的方案。2015年,英特尔先是天价收购了FPGA的制造商Altera,一年后又收购了Nervana,为全新一代AI加速器芯片组奠定了基础。
去年12月,英特尔再次花掉20亿美元高价收购了成立仅3年的以色列数据中心AI芯片制造商Habana Labs。与英伟达收购Mellanox一样异曲同工,通过收购Habana,英特尔也将补足数据中心场景下的通信和AI两种能力。
受到这一收购的激励,英特尔宣布停止去年8月才发布的用于AI训练的Nervana NNP-T,转而专注于推进Habana Labs的Gaudi和Goya处理器产品,以对标英伟达的tesla V100和推理芯片T4。此外,一款基于Xe架构的GPU也将在今年中旬面世。
在软件层面,为应对异构计算带来的挑战,英伟达在去年11月发布了OneAPI公开发行版。不管是CPU、GPU、FPGA还是加速器,OneAPI都尝试最大程度来简化和统一这些跨SVMS架构的创新,以释放硬件性能。
尽管英特尔以“全力以赴”的姿态投入到AI计算当中,通过四处出手收编了涵盖GPU、FPGA 到ASIC的AI芯片产品阵列,并建立了广泛适用的软硬件生态。但是在挑战英伟达的通用GPU产品上面,仍然还有一定距离。

首先,英特尔通过CPU适用于AI计算的策略一直未能得到主要云计算厂商的青睐,大多数厂商仍然乐于选择CPU+GPU或FPGA的方案来部署其AI训练的硬件方案。而GPU仍然是英伟达的主场,V100和T4仍然是当下数据中心主流的通用GPU和推理加速器。
其次,英特尔在AI芯片的布局才刚刚发力,受到Nervana AI芯片一再延迟的影响,Habana产品才刚刚开始进行整合,这将使得英特尔短期内难以挑战英伟达的AI服务器芯片的市场份额。
而现在英伟达最新的安培架构的A100 GPU以及AI系统集群的发布,更是给英特尔以及市场其他竞争对手一场饱和攻击。尽管说,长期来看云计算厂商和AI服务器芯片厂商开发的定制芯片会侵蚀一部分GPU的份额,而如今都要先跨越英伟达A100所搭起的AI计算的坚壁与高墙。
AI计算升级,带来数据中心全新布局方案
我们先看数据中心本身的变化。受到AI相关应用需求和场景的爆发式增长,中小型数据中心无法承受如此巨量的“AI计算之痛”,市场对超大型数据中心的需求越发强烈。
第一,以亚马逊AWS、微软Azure、阿里、谷歌为代表的公有云巨头,正在占据超大型数据中心的主要市场份额。一方面,超大型数据中心将带来更多的服务器及配套硬件的增长;另一方面,AI算法的复杂度增加和AI处理任务的持续增长,又需要服务器的配置以及结构得到持续升级。
在一些视觉识别为主的AI企业,建立一个超算中心就需要部署上万块GPU,对于那些TOP级云服务商的云计算数据中心,为支持深度学习训练任务,所需要的GPU量级也将是海量级别。
第二,云服务厂商都在推出自研的芯片,来缓解因为价格昂贵和数据量巨大而带来的GPU计算成本飙升的问题。这些厂商推出的大多是推理芯片,以节省GPU的通用算力。但这些推理芯片只在通用性上面的不足,造成其很难突破自研自用的局面。
那么,英伟达的A100 GPU芯片的发布,对云计算数据中心带来哪些新的变化呢?或者说为AI服务器芯片的对手们设立了怎样的门槛呢?
首先,作为采用全新的安培架构的A100 GPU,支持每秒1.5TB的缓冲带宽处理,支持TF32 运算和FP64双精度运算,分别带来高达20倍FP32的AI计算性能和HPC应用2.5倍的性能提升。此外还包括MIG 新架构、NVLink 3.0以及AI运算结构的稀疏性等特性,这些使得 A100 加速卡不仅可用于AI训练和AI推理,还可以用于科学仿真、AI对话、基因组与高性能数据分析、地震建模及财务计算等多种通用计算能力。而这一解决方案有可能缓解很多云服务厂商在推理上面的计算压力,也对其他厂商的推理芯片带来一定的竞争压力。
其次,英伟达发布的第三代的DGX A100的AI系统在提高吞吐量同时,大幅降低数据中心的成本。由于A100内置了新的弹性计算技术,可以分布式的方式进行灵活拆分,多实例 GPU 能力允许每个 A100 GPU 被分割成多达七个独立的实例来推断任务,同时也可以将多个A100作为一个巨型 GPU 运行,以完成更大的训练任务。

(“The more you buy,the more money you save!”)
用黄仁勋举的例子来说,一个典型的AI数据中心有50个DGX-1系统用于AI训练,600个CPU系统用于AI推理,需用25个机架,消耗630kW功率,成本逾1100万美元;而完成同样的工作,一个由5个DGX A100系统组成的机架,达到相同的性能要求,只用1个机架,消耗28kW功率,花费约100万美元。
也就是说,DGX A100系统用一个机架,就能以1/10的成本、1/20的功率、1/25的空间取代一整个AI数据中心。

总体而言,英伟达用一套性能惊人又极具创新性的AI计算架构与AI服务器芯片硬件,带来了AI数据中心计算平台的全新升级。英伟达的野心将不再只是提供性能升级的GPU硬件产品,而是要重新定义数据中心的AI计算的规则,将数据中心视作基本的计算单元。
实际来讲,一个DGX A100 GPU系统的单价就要20万美元,对于要为了AI训练而采购成千上万块企业级GPU的云计算厂商来说,可想而知成本将有多高。现在,也只有全球主要的云计算厂商、IT巨头以及政府、实验室为DGX A100下了初始订单。
对于其他竞争对手而言,英伟达这次在AI服务器芯片及AI数据中心计算平台铸就的坚壁高墙,似乎在短期内难以逾越。同时,也会成为未来几年,AI服务器芯片厂商努力去对标的性能标准。当然,对英伟达A100的挑战,也自然就此开始。至于是英特尔、AMD还是AWS、谷歌,我们拭目以待。
